
Kubernetes bietet zahlreiche Abstraktionen und APIs, die das Betreiben von entkoppelten, containerisierten Microservice-Architekturen einfacher machen. Wir zeigen Ihnen, welche das sind und wie Sie diese einsetzen.
In unseren ersten drei Teilen, finden Sie eine Einführung in Kubernetes:
Containerorchestrierung mit Kubernetes - Teil 1
Containerorchestrierung mit Kubernetes - Teil 2
Containerorchestrierung mit Kubernetes - Teil 3
Kubernetes-Objekte
Kubernetes enthält eine Reihe von Abstraktionen, die den Zustand des Systems darstellen: eingesetzte Containeranwendungen und Workloads sowie zugehörige Netzwerk-und Festplattenressourcen, Policies und weitere Informationen. Diese Objekte können über die Kubernetes-API verwaltet werden.
- Pods können mehrere Container enthalten. Die Container eines Pods werden gemeinsam als Einheit scheduled und befinden sich immer auf dem gleichen Node. Sie teilen sich einen gemeinsam genutzten Kontext, z.B. den Network Namespace (sie können sich gegenseitig unter "localhost" erreichen) und Volume Mounts (sie können auf ein gemeinsames Dateisystem zugreifen). Ein Pod modelliert sozusagen einen "logischen Host" auf dem die enthaltenen, eng miteinander gekoppelt Container gemeinsam ausgeführt werden.
- Services sind eine Abstraktion, die Pods logisch gruppiert, mit denen Service-Endpunkte definiert und Zugriffskontrolle, Lastverteilung, Discovery und DNS ermöglicht werden können.
- Namespaces (Namensräume) bieten Isolations- und Zugriffskontrolle für Teams oder Projekte, um einen Cluster in Sub-Cluster partitionieren zu können. Die Namen der Ressourcen in einem Namespace sind eindeutig, nicht jedoch Namespace-übergreifend. In "kube-system" sind die Ressourcen des Kubernetes-Systems enthalten.
- Volumes sind im wesentlichen Verzeichnisse, das den Containern in einem Pod zugänglich ist. Durch den Volumentyp wird bestimmt, wie und wo dieses Verzeichnis entsteht.
Kubernetes-Controller
Darüber hinaus enthält Kubernetes eine Reihe von höherwertigen Abstraktionen, die als Controllers bezeichnet werden. Die Controller bauen auf den Basisobjekten auf und bieten zusätzliche Funktionalität.
- ReplicaSets sorgen dafür, dass die gewünschte Anzahl an gleichartigen Pods (Replikaten) im Cluster aktiv sind.
- StatefulSets dient dem Management zustandsbehafteter Workloads, z.B. Datenbanken
- Deployments beschreiben den gewünschten Zustand an Pods und ReplicaSets deklarativ, sowohl für die initiale Ausbringung als auch für Updates und können "zurückgerollt" werden.
- Ingress-Objekte sind eine leistungsfähige Möglichkeit, um mehrere Services zu einer von extern erreichbaren API zu kombinieren.
- PersistentVolumes bzw. PersistentVolumeClaims bieten eine Abstraktion für persistenten Speicher, dessen konkrete Ausprägung vom Volume-Type abhängt, z.B. ein Verzeichis auf dem Node.
- DaemonSets stellen sicher, das ein Pod auf allen oder bestimmten Nodes läuft, z.B. ein Agent für das Sammeln von Logs
- Jobs erzeugen einen oder mehrere Pods und sorgen dafür dass die spezifizierte Anzahl von ihnen erfolgreich terminiert, z.B. für Initialisierungen
- CronJobs erzeugen Jobs periodisch in einem festgelegten Zeitplan
Deklarative Beschreibung des gewünschten Zustands
Kubernetes arbeitet deklarativ - der Benutzer beschreibt den gewünschten Zustand und die Kubernetes Controller sorgen dafür, dass dieser gewünschte Zustand hergestellt und beibehalten wird. Die erforderlichen Aktionen werden dabei von den Controllern ermittelt, automatisch ausgeführt und im laufenden Betrieb überwacht und wieder hergestellt (Kubernetes verwendet intern "reconciliation loops"). Dieses Modell ist einfacher für die Anwender und ermöglicht Selbstheilung und Skalierung.
Wenn ein Pod mit drei Replikaten bereitgestellt wurde und ein Pod beendet wird, so startet Kubernetes einen neuen Pod. Wird per kubectl manuell ein vierter Pod erzeugt, so wird Kubernetes einen der vier Pods beenden, da die gewünschte Anzahl drei beibehalten werden soll. Um eine Skalierung auf vier Pods zu erreichen, muss also der gewünschte Zustand als "vier Pods" deklariert werden, Kubernetes sorgt dann dafür, dass dieser Zustand erreicht wird.
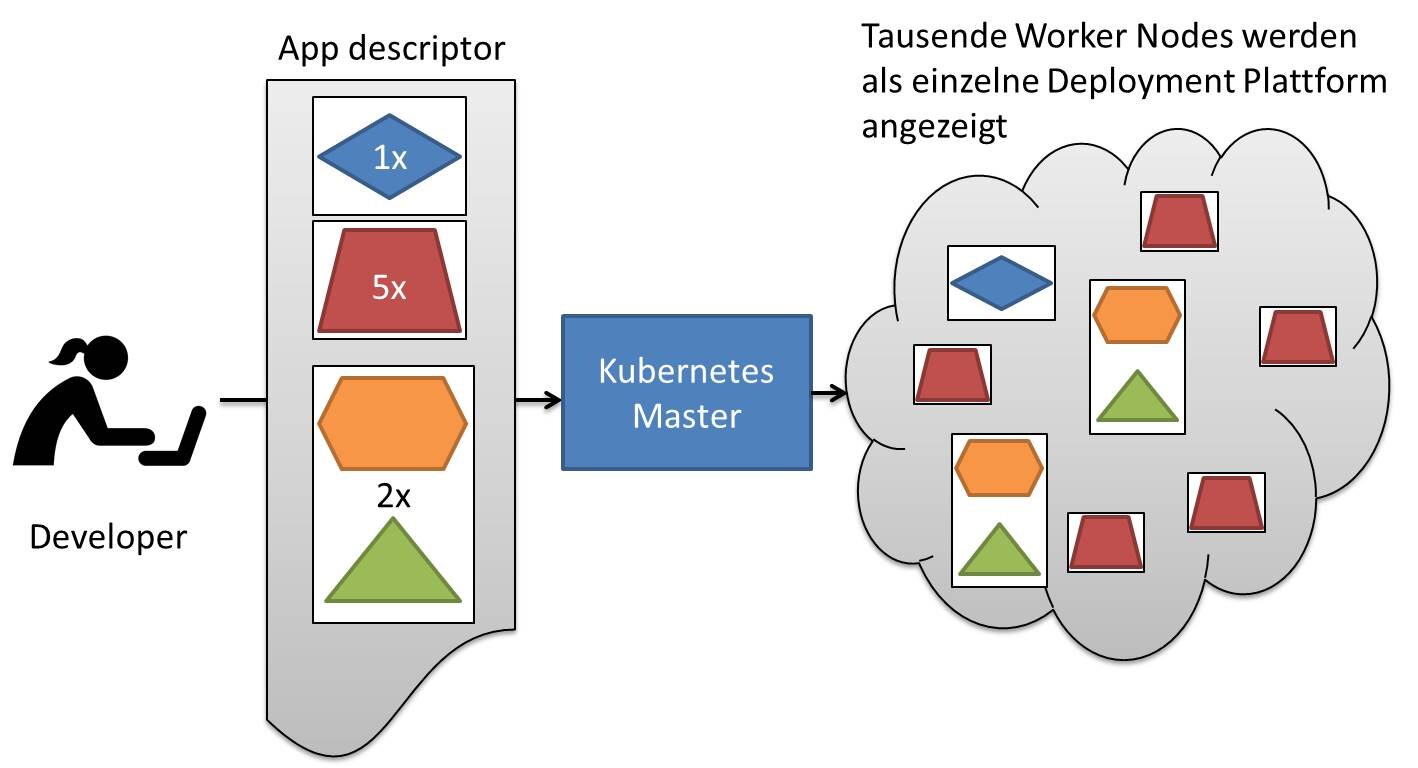
App Deployment: Kubernetes-zeigt-das-ganze-Datencenter-als-eine-einzige-Deployment-Plattform
Anwendungsbereitstellung
Die Elemente der bereitzustellenden containerisierten Anwendung werden im Sinne der deklarative Konfiguration als Kubernetes-API-Objekte in Textdateien (Manifest) in JSON- oder YAML-Format beschrieben.
Im Allgemeinen wird YAML bevorzugt, weil es besser lesbar ist und mit Kommentare versehen werden kann.
Beispielsweise wird ein Deployment deklariert, das aus einem ReplicaSet mit Web-App-Frontend-Pods, einem ReplicaSet mit REST-Service-Pods, einem Stateful-Set für die Datenbank-Pods und den entsprechenden Services besteht.
Mit diesem Manifest kann die Anwendung per kubectl-Aufruf in den Cluster deployed werden.
Der API-Server von Kubernetes übernimmt Dateien und verarbeitet sie, bevor er sie im persistenten Storage (etcd) ablegt. Der Scheduler erkennt, dass die Pods noch nicht auf einem Knoten geschedult wurden. Er weist die Pods den Nodes zu, die die Ressourcen und anderen Bedingungen aus dem Pod-Manifest erfüllen können. Für die Service-Discovery stellt Kubernetes eine stabile interne Cluster-IP-Adresse und einen DNS-Namen für die deklarierten Services bereit. Wenn ein Container, der in einem Kubernetes-Pod ausgeführt wird, eine Verbindung mit einer Adresse eines anderen Service im Cluster herstellt, wird die Verbindung von einem lokalen Agenten (Kube-Proxy) an einen der entsprechenden Ziel-Container weitergeleitet.
Für die Parametrisierung der Manifeste für verschiedene Umgebungen gibt es Tools wie z.B. "kustomize".
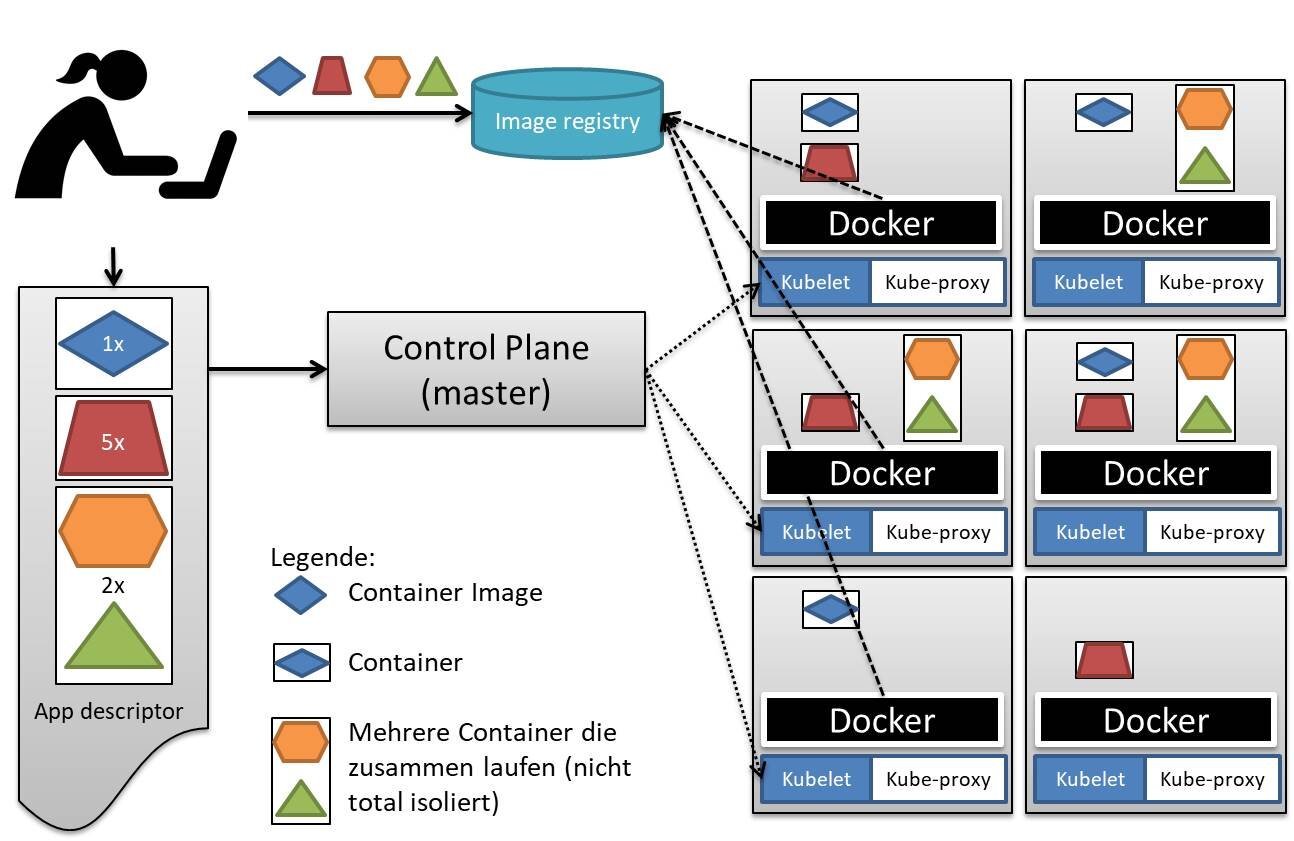
App Deployment:Ein grundlegender Überblick der Kubernetes-Architektur und Apps die darauf laufen
Zugriffskontrolle / Access-Control
Kubernetes besitzt selbst keine Benutzerverwaltung. Dies ist allerdings kein Nachteil, da in den meisten Umgebungen ohnehin bereits ein System existiert.
Um eine einfache Integration zu ermöglichen, können verschiedene Authentifizierungsverfahren konfiguriert werden:
- Basic-Authentication
- Zertifikatsbasierte Authentication
- openID Connect / JWT-Token
- weitere Verfahren via Webhook
Für die Autorisierung stehen ebenfalls verschiedene Mechanismen zur Auswahl:
- Attributsbasierte Access-Control (ABAC) - Policies mit Attributen
- Rollenbasierte RBAC - Regulierung des Zugriffs basierend auf den Rollen von Benutzern und der Definition von (Cluster-) Roles und (Cluster-) RoleBindings, mit dem berechtigte Benutzer (z.B. Cluster-Admins) für jeden Pod individuell Kubernetes-API-Aufrufe erlauben können
- weitere Verfahren via Webhook
Für die Spezifikation granularer Zugriffs-Policies wie z.B. Zugriffs-Limits, Einhaltung von best-practices, Setzen von Standardwerten können die zahlreichen eingebauten AdmissionController genutzt werden wie z.B.
- ResourceQuota
- PodSecurityPolicy
- DefaultStorageClass
- ...
- zusätzliche per Webhook
Für die Steuerung der Berechtigungen der Prozesse innerhalb es Clusters gibt es das Konzept der ServiceAccounts, z.B. um Zugriffe von Pods auf die Kubernetes-API selektiv zu erlauben.
Health-Check
Kubernetes unterstützt vom Benutzer implementierte Health-Checks. Diese Überprüfungen werden vom kubelet auf den Worker-Nodes ausgeführt um sicherzustellen, dass der entsprechende Container ordnungsgemäß funktioniert. Tut er das nicht wird er von Kubernetes entfernt und eine neue Kopie gestartet.
Derzeit unterstützt Kubernetes drei Arten von Gesundheitschecks:
- HTTP-Statusprüfung: Das kubelet ruft einen definierten Web-Endpunkt auf. Wenn der Antwortcode zwischen 200 und 399 liegt, wird dies als Erfolg betrachtet.
- Container exec: Das kubelet führt einen Befehl innerhalb des Containers aus. Wenn "OK" zurückgegeben wird, gilt dies als Erfolg.
- TCP-Socket: Das kubelet versucht, einen Socket für den Container zu öffnen und eine Verbindung herzustellen. Wenn die Verbindung hergestellt ist, gilt sie als fehlerfrei.
Meist ist ein einfacher Prozess-Check nicht ausreichend. Wenn der Prozess aufgrund eines Deadlocks keine Requests mehr bedienen kann, wird ein Prozess-Health-Check das Problem nicht erkennen, da der Prozess weiterhin läuft. Deshalb führen Liveness-Health-Checks anwendungsspezifische Logiken durch, um zu prüfen, dass der Prozess auch korrekt arbeitet.




